artykuły
projekty
Intel 8086 i okolice 16 bitów
Po sukcesie mikrokomputerów 8-bitowych przyszła pora na przejmowanie przez mikroprocesory obszarów wymagających większej mocy obliczeniowej, zarezerwowanych do tej pory dla tzw. minikomputerów. Do tego potrzebna była, oprócz szybkości, bardziej elastyczna architektura, możliwość obsługi większej pamięci i współpraca z dodatkowymi jednostkami obliczeniowymi. Kolejny krok w ewolucji stał się nieuchronny.
Problemy z klasyfikacją i metodologia pomiarowa
Zanim przejdziemy do omówienia wybranych reprezentantów kolejnego etapu ewolucji mikroprocesorów, należy doprecyzować i wyjaśnić kilka kwestii.
Wszędzie tam, gdzie fizyczne wyprowadzenia procesora mają więcej niż jedną funkcję, jest to oznaczone linią przerywaną. Takie multipleksowanie sygnałów stosuje się głównie ze względu na ograniczoną liczbę wyprowadzeń, rzadziej z powodu decyzji projektantów mikroarchitektury.
Podawany dla każdego modelu indeks prędkości jest prostym odzwierciedleniem najkrótszego czasu wykonania instrukcji przy danej częstotliwości taktowania. Każdy cykl instrukcji składa się z jednego lub więcej cykli maszynowych (np. cykl pobrania kodu rozkazu z pamięci), a te z kolei z jednego lub więcej cykli zegara. Najkrótszy lub podstawowy cykl instrukcji oddaje istotną cechę architektury, dlatego został wybrany jako podstawowy wyznacznik prędkości.
Podobnie jak w poprzednich odcinkach cyklu, podstawowym benchmarkiem jest dodawanie liczb całkowitych, 64-bitowych, zapisanych w pamięci. Czas wykonania tego działania jest również bazą dla wyliczenia współczynnika efektywności architektury. Pokazuje on, w jakim stopniu poziom komplikacji mikroprocesora przekłada się na jego zdolność do wykonywania prostych operacji arytmetycznych. Został on zdefiniowany następująco:
\[\text{efektywność architektury} = \frac{\text{ilość 64-bitowych dodawań na sekundę}}{\text{ilość tranzystorów w tysiącach}}\]Przy obliczaniu czasu wykonania, mechanizm pobierania wstępnego i kolejkowania jest brany pod uwagę tylko o tyle, o ile jest on uwzględniony w czasach wykonania podanych w materiałach producenta. Jest to zabieg celowy, z jednej strony mający na celu wyeliminowanie czynników o charakterze niedeterministycznym, a z drugiej możliwość porównania architektur prostych i bardziej wyrafinowanych. Autor jest świadomy potencjalnie dużego wpływu na rzeczywistą, średnią wydajność, jaką może mieć zastosowanie wyżej wymienionych technologii. Wybór takiego współczynnika ma na celu pokazanie, jak wielki narzut na „surową” moc obliczeniową mają mechanizmy związane z wielozadaniowością, trybem chronionym czy stronicowaniem, które są wbudowane w nowoczesne mikroprocesory. Jest to cena, jaką płacimy za wszechstronność i elastyczność rozwiązań sprzętowych, którą warto jest sobie uświadomić.
Ważnym aspektem klasyfikacji procesorów jest przypisanie ich do rodziny 8, 16 lub 32-bitowej. Czasami bywa to jednak niejednoznaczne i trudne, istnieje bowiem kilka kryteriów, których można użyć. Może to być szerokość szyny danych (zewnętrznej lub wewnętrznej), rozmiar danych przetwarzanych przez wewnętrzne ALU (ang. Arithmetic Logic Unit - jednostka arytmetyczno-logiczna) lub rozmiar rejestrów mikroprocesora. Mikroprocesor może zostać przypisany do więcej niż jednej kategorii i w związku z tym jego zaklasyfikowanie jest w pewnym stopniu umowne.
Intel 8086
Poprzednie konstrukcje firmy Intel, od i4004 począwszy, przez i8008 oraz i8080, pokazują przyjęty przez nią kierunek rozwojowy. Ta filozofia sprowadza się do wykorzystania najnowszej technologii w celu stworzenia architektury, która w krótkim terminie pozwoli uchwycić i utrzymać istotny segment rynku. Wymaga to najczęściej kompatybilności z poprzednimi modelami, co umożliwia wykorzystanie gotowej już bazy programów i użytkowników. Marketingowo takie podejście jest najczęściej skuteczne, jednak z inżynieryjnego punktu widzenia ma swoje, dosyć istotne, wady.
Pierwotnie Intel rozpoczął ambitny projekt iAPX 432, który miał posłużyć do stworzenia konkurencji dla maszyn klasy mainframe, jednak jego ukończenie wciąż się przeciągało. Był to w owym czasie bardzo zaawansowany projekt, co znalazło odzwierciedlenie w nazwie, którą można by przetłumaczyć jako „Zaawansowana Architektura Przetwarzająca firmy Intel” (ang. Intel’s Advanced Processing Architecture - gdzie „X” to prawdopodobnie greckie „chi” w słowie architecture). Prace nad projektem rozpoczęły się w 1975 roku, procesor miał składać się z dwóch niezależnych układów scalonych: sekwencera/dekodera oraz jednostki wykonawczej. Miał zawierać wszystkie wyrafinowane mechanizmy wspomagające programowanie w językach wysokiego poziomu włącznie z implementacją garbage collectora, wielozadaniowości i programowania obiektowego na poziomie mikrokodu. Miał powstać dedykowany system operacyjny iMAX 432, napisany w języku Ada, który wykorzystałby wszystkie zalety iAPX 432.
Po sukcesie Z80 firmy Zilog, który był binarnie zgodny z popularnym i8080, a jednocześnie tańszy, bardziej wszechstronny i szybszy, Intel musiał szybko zaproponować nowy produkt. Niestety projekt iAPX 432 z powodu zbyt dużego poziomu złożoności okazał się nierealistyczny i został zarzucony na rzecz prostszego, lecz będącego w zasięgu, projektu i8086. Widoczną spuścizną iAPX 432 została zmiana konwencji nazewniczej - i tak Intel 8086 jest znany również jako iAPX 86. W ofercie pojawił się również i8088 (iAPX 88), który był zewnętrznie 8-bitowy i stanowił „budżetową” wersję i8086, w pełni zgodną programowo, lecz o nieco mniejszej wydajności.
Od początku i8086 został zaprojektowany tak, by przenoszenie kodu z i8080 było na poziomie asemblera jak najprostsze. Nie została jednak zachowana zgodność na poziomie kodu maszynowego. Intel 8086 jest mikroprocesorem 16-bitowym o architekturze dużo bardziej wszechstronnej niż jego 8-bitowy poprzednik (Rysunek 1). Pomimo pewnej inercji architektonicznej 16-bitowy mikroprocesor Intela jest jednak dużym krokiem naprzód.
Pierwszą, rzucającą się w oczy zmianą jest funkcjonalny podział jednostki centralnej na blok BIU (ang. Bus Interface Unit - jednostka interfejsu magistrali) i EU (ang. Execution Unit - jednostka wykonawcza). Cykl pobrania i wykonania rozkazów w dalszym ciągu składa się ze standardowych czterech faz:
- Pobranie z pamięci i zdekodowanie kolejnej instrukcji (ang. fetch - pobierz).
- Odczyt operandu, jeśli instrukcja tego wymaga (ang. read - odczytaj).
- Wykonanie instrukcji (ang. execute - wykonaj).
- Zapis wyniku, jeśli instrukcja tego wymaga (ang. write - zapisz).
Dzięki separacji BIU i EU faza pobrania kolejnej instrukcji może odbywać się równolegle z fazą wykonywania poprzedniej. Proces ten jest wspomagany kolejką FIFO o długości 6 B łączącą oba moduły. Technika modularyzacji stanie się defacto standardem w projektowaniu mikroprocesorów kolejnych generacji. Pierwsze próby zastosowania pipeliningu (potokowości) były obecne już wcześniej, np. w MOS 6502, lecz teraz przybrały bardziej dojrzałą formę.
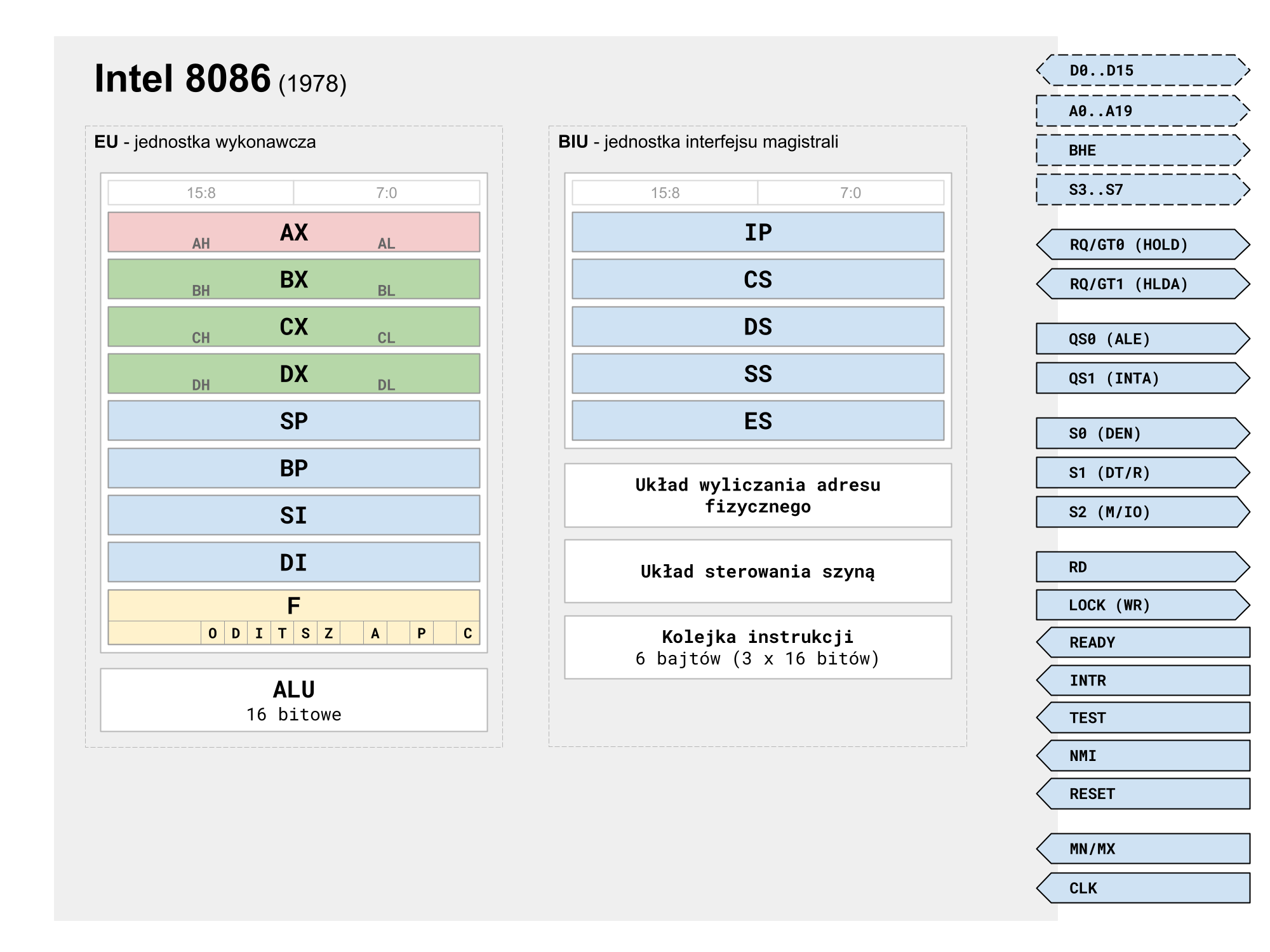 Rysunek 1. Schemat blokowy mikroprocesora Intel 8086
Rysunek 1. Schemat blokowy mikroprocesora Intel 8086
Wewnętrzna architektura składa się z 16-bitowych rejestrów ogólnego przeznaczenia o częściowo specjalizowanych funkcjach.
| rok wprowadzenia do produkcji | 1978 |
| ilość tranzystorów | 29000 |
| częstotliwość taktowania | 5 MHz (cykl zegarowy: 0.2 μs) |
| najkrótszy cykl instrukcji | 0.4 μs (2 cykle zegarowe) |
| indeks prędkości | 2.5 MIPS |
| dodawanie 64-bitowe | 22727 / s |
| efektywność architektury | 784 |
| typ architektury | 16-bitowa, CISC |
| kolejność bajtów | little-endian |
| licznik programu | 16-bit segment : 16-bit offset |
| wskaźnik stosu | 16-bit segment : 16-bit offset |
| rejestry ogólnego przeznaczenia | 7 x 16-bit |
| rejestry segmentowe | 4 x 16-bit |
| ALU | 16-bit ogólnego przeznaczenia |
| adresowanie pamięci | 1 MiB (20-bit) adresowanie segmentowe |
| adresowanie portów | 64 KiB portów we/wy |
| przerwania sprzętowe | niemaskowalne/maskowalne |
| przerwania programowe | maskowalne, w/g priorytetów, 256 kodów identyfikujących |
| dzielenie i mnożenie liczb całkowitych | tak |
| tryby pracy | minimalny/maksymalny |
| praca z koprocesorem | tak (np. Intel 8087, 8089) |
| systemy wieloprocesorowe | tak |
Znaczniki:
O– przepełnienieD- kierunek dla operacji łańcuchowychI- maska przerwańT- pułapka przy pracy krokowejS- znakZ- zeroA- przeniesienie pomocniczeP- parzystośćC- przeniesienie
Tryby adresowania:
- bezpośrednie
- pośrednie rejestrowe (z przesunięciem)
- bazowe (z przesunięciem)
- indeksowane (z przesunięciem)
- bazowe indeksowane (z przesunięciem)
- blok danych
- względne
16-bitowe rejestry danych AX, BX, CX, DX są dostępne w modelu programowym również jako 8-bitowe połówki (np. AL, AH), co pozwala na przyspieszenie wykonywania rozkazów i skrócenie ich długości w przypadku użycia adresowania natychmiastowego. Z przyczyn ekonomicznych i8086 był oferowany w obudowie o 40-tu wyprowadzeniach, co wymusiło multipleksowanie szyny danych i szyny adresowej. Dzięki możliwości użycia 8-bitowego operandu wystarczał pojedynczy cykl dostępu do szyny danych.
Dostępne są również 16-bitowe rejestry z grupy tzw. wskaźników i indeksów (ang. pointer and index group):
SP- wskaźnik stosu (ang. stack pointer)BP- wskaźnik bazy (ang. base pointer).SI- indeks źródła (ang. source index).DI- indeks przeznaczenia (ang. destination index).
Wspierają one całkiem wygodny mechanizm adresowania, w którym adres efektywny jest sumą wartości odpowiedniego rejestru bazowego (wskaźnikowego), indeksowego oraz opcjonalnego przesunięcia (ang. offset). Dodatkowym ułatwieniem jest - przy transferach blokowych - określenie, czy indeks ma być automatycznie inkrementowany czy dekrementowany po przesłaniu każdego bajtu. Rejestr CX może być w takim przypadku wykorzystany jako dedykowany licznik powtórzeń pętli, co pokazuje poniższy przykład:
LDS SI, SRC ; ładuj adres danych źródłowych do DS:SI
LES DI, DST ; ładuj adres bufora docelowego do ES:DI
MOV CX, 1000 ; ładuj licznik bajtów do przesłania
CLD ; ustaw znacznik kierunku na inkrementację
REP MOVSB ; wykonaj transfer blokowy DS:SI -> ES:DI
Efektywny adres w trybie adresowania segmentowego jest wyliczany w następujący sposób:
20-bit adres efektywny = 16-bit adres segmentu x 16 + 16-bit offset
Powstały w ten sposób 20-bitowy adres fizyczny pozwala na zaadresowanie 1 MiB pamięci. W przypadku instrukcji MOVSB standardowo dane źródłowe są pobierane z segmentu DS, a zapisywane w segmencie ES.
Do wyboru są następujące rejestry segmentowe:
DS- segment danych (ang. data segment).CS- segment programu (ang. code segment).SS- segment stosu (ang. stack segment).ES- segment dodatkowy (ang. extra segment)
Każdy z nich ma swoje domyślne zastosowanie w kontekście określonych operacji - ma to zresztą odzwierciedlenie w ich nazwach. Tak np. adres aktualnie wykonywanej instrukcji określa para CS:IP, aktualny wierzchołek stosu określa para SS:SP. Dla instrukcji MOV domyślnym segmentem jest DS, można jednak explicite podać inny segment.
Poniższy kod realizujący nasz standardowy benchmark pokazuje w praktyce wykorzystanie idei transferów blokowych.
; Intel 8086 (iAPX 86)
; dodawanie dwóch liczb 64-bitowych
; ARG0, ARG1 - etykiety buforów zawierających argumenty
; wynik zapisywany jest w ARG1, dane zorganizowane są w 16-bitowe słowa
; kolejność bajtów w słowie zgodna z wymaganą przez architekturę procesora
; zakładamy, że segmenty ES i DS są sobie równe
MOV SI, offset ARG0 ; (4) ładuj adres argumentu 0 do SI
MOV DI, offset ARG1 ; (4) ładuj adres argumentu 1 do DI
MOV CX, 4 ; (4) ustaw licznik słów
CLD ; (2) ustaw znacznik kierunku na inkrementację
CLC ; (2) zeruj znacznik przeniesienia
NST:
LODSW ; (12) ładuj blokowo kolejne słowo ARG0 do AX
ADC AX,[DI] ; (14) dodaj kolejne słowo z ARG1 do AX
STOSW ; (11) zapisz blokowo AX do kolejnego słowa ARG1
LOOP NST ; (17) kontynuuj dla następnego słowa
Sumując czasy wykonania dostajemy: 16 + 4 x 54 - 12 (ostatni skok warunkowy nie zachodzi, więc zajmuje mniej cykli) = 220 cykli zegara. Czas wykonania wynosi więc 44 μs, co daje 22727 dodawań na sekundę.
Istnieją również instrukcje blokowe, wykorzystujące ten sam schemat adresowania i inkrementacji/dekrementacji, realizujące skanowanie (wyszukiwanie zera) i porównywanie. W tym kontekście operacje te zwane są również łańcuchowymi (ang. string operations).
System przerwań został wzbogacony o możliwość identyfikacji źródła za pomocą 8-bitowego kodu. Sprzętowe przerwanie maskowalne wyzwalane jest sygnałem INTA, pierwszy impuls ma charakter aktywacji, podczas drugiego na szynie danych powinien znaleźć się 8-bitowy kod przerwania. Kod ten jest wykorzystywany przez CPU do odnalezienia odpowiedniego wektora obsługi przerwania i skoku pod zawarty w nim adres. Standardowo koordynacją sprzętowej obsługi przerwań zajmuje się dedykowany układ scalony Intel 8259A. Przerwanie może zostać wyzwolone również programowo za pomocą instrukcji INT, w której parametrem jest kod przerwania.
Ważnym krokiem w rozwoju architektury mikroprocesorów, zrealizowanym na przykładzie i8086, było ułatwienie tworzenia systemów wieloprocesorowych. Nie było to jednak w owych czasach rozwiązanie często stosowane, dlatego wyposażono i8086 w dwa tryby pracy: minimalny i maksymalny. Wyboru trybu pracy dokonywało się przez podanie odpowiedniego stanu na wyprowadzenie MN/MX. Tryb minimalny był dedykowany dla nieskomplikowanych systemów jednoprocesorowych, w którym sygnały dostępu do magistrali: HOLD/HLDA i sygnały sterujące: DT/R, DEN, ALE, M/IO generuje sam mikroprocesor. W trybie maksymalnym na zewnątrzy wyprowadzone były syntetyczne sygnały określające wewnętrzny stan mikroprocesora: S0..S2, QS0..1, RQ/GT0..1 wykorzystywane przez dodatkowe układy, jak Intel 8288 (kontroler magistrali) czy Intel 8289 (arbiter). Były to elementy tzw. architektury Intel Multibus. Tego typu rozwiązania nie były stosowane w konstrukcjach 8-bitowych, były jednak standardem w minikomputerach i maszynach klasy mainframe. Mikroprocesor nie był jednak wyposażony w tzw. tryb chroniony (ang. protected mode), ograniczający dostęp do określonych instrukcji i zasobów dla programów użytkownika.
Idea współpracy mikroprocesora z innymi jednostkami przetwarzającymi, tzw. koprocesorami (ang. co-processor), zaowocowała również wprowadzeniem do sprzedaży koprocesora Intel 8087, który zajmował się sprzętową realizacją arytmetyki zmiennoprzecinkowej (ang. floating-point arithmetic). Ta klasa procesorów często określana jest jako FPU (ang. floating-point unit - jednostka zmiennoprzecinkowa) w odróżnieniu od CPU (ang. central processing unit - centralna jednostka przetwarzająca, procesor).
Zazwyczaj koprocesor pobiera swoje rozkazy za pośrednictwem procesora głównego (ang. host processor), który realizuje dostęp do operandów łącznie z wyliczaniem ich adresu efektywnego i pobieraniem ich z pamięci. W przypadku i8086 sekwencja obsługi instrukcji koprocesora rozpoczyna się od instrukcji ESC i wygląda następująco:
instrukcja ESC jest dekodowana jednocześnie przez procesor i koprocesor. Koprocesor przechodzi po niej w stan aktywny, ponieważ kolejna instrukcja jest dedykowana dla niego.
jeśli instrukcja koprocesora nie wymaga pobrania operandów, jest natychmiast przez niego wykonywana, a procesor główny od razu przechodzi do kolejnej instrukcji.
jeśli instrukcja koprocesora wymaga operandu, procesor główny pobiera go z pamięci, ponieważ tylko on potrafi wyliczyć adres efektywny. Operand i adres zostają przechwycone przez koprocesor, który ewentualne kolejne bajty operandu pobiera już samodzielnie. Procesor główny przechodzi do wykonywania kolejnej instrukcji.
początek przetwarzania rozkazu przez koprocesor sygnalizowany jest ustawieniem wyjścia BUSY, które połączone jest z wejściem TEST procesora głównego. Daje to możliwość synchronizacji ich pracy, o czym więcej w dalszej części artykułu .
Procesor główny nie jest wstrzymywany na czas wykonywania przez koprocesor swojej instrukcji. Synchronizację (oczekiwanie na wynik) realizuje się po stronie procesora głównego przez wykonanie instrukcji WAIT. Sprawdza ona wejście TEST, co wstrzymuje wykonywanie do czasu zakończenia przetwarzania przez koprocesor.
Koordynację pracy obu procesorów, szczególnie podczas konieczności pobierania przez Intel 8087 dodatkowych bajtów operandu, realizują specjalizowane układy logiczne i wspomniany wcześniej kontroler magistrali Intel 8288. Praca z koprocesorem jest możliwa tylko w trybie maksymalnym.
Powyżej zaprezentowany schemat współpracy procesora głównego z koprocesorem, który efektywnie rozszerza dostępny zestaw instrukcji, jest stosowany w mniej lub bardziej podobny sposób przez pozostałe, omówione w dalszej części artykułu, konstrukcje. Firma Intel oferuje oprócz koprocesora numerycznego również koprocesor wejścia/wyjścia - Intel 8089.
W celu koordynacji dostępu do współdzielonych zasobów w systemach wieloprocesorowych dostępny jest modyfikator instrukcji (ang. prefix) LOCK, który sygnalizuje wyłączny dostęp do szyny i w połączeniu z instrukcją XCHG (wymiana danych pomiędzy rejestrem i pamięcią) pozwala na implementację semaforów.
Podsumowując, architektura mikroprocesora Intel 8086 jest znacznie bardziej zaawansowana niż jej 8-bitowych poprzedników. Charakterystycznym rysem konstrukcji Intela pozostaje w dalszym ciągu tendencja do tworzenia wyspecjalizowanych rozwiązań i dedykowanych dla nich rejestrów czy instrukcji mających w wydajny i zwięzły sposób realizować określone funkcje. Pozwala to tworzyć naprawdę wydajne rozwiązania, lecz nieuchronnie prowadzi do rozrastania się zestawu „wyspecjalizowanych narzędzi”, różniących się od siebie i wymagających opanowania każdego z osobna. Jest to podejście charakterystyczne dla projektantów rozwiązań sprzętowych, które raz wdrożone pozostają w zasadzie niezmienne, stąd potrzeba „obejść” i „rozszerzeń” staje się jedyną drogą rozwoju.
Zilog Z8001
Firma Zilog została założona przez pracowników firmy Intel pracujących nad pierwszym mikroprocesorem - Intel 4004. Pierwszym komercyjnym sukcesem firmy Zilog był Z80, binarnie kompatybilny z Intel 8080, lecz przy tym bardziej uniwersalny, szybszy i tańszy. Udoskonalanie istniejących konstrukcji pozwalające uczyć się na błędach poprzedników i jednocześnie wykorzystywać postęp technologiczny jest bardzo efektywną strategią. Jednak w przypadku rodziny Z8000 firma Zilog postanowiła zrezygnować z tej drogi i zaproponować autentycznie nowe, nie obarczone wymogami wstecznej kompatybilności, rozwiązanie. W ramach rodziny Z8000 powstały na początku dwie konstrukcje: bardziej rozwinięta Z8001 i ograniczona oraz tańsza Z8002. W tym artykule omówiona zostanie tylko pierwsza z nich.
Poglądowy schemat architektury mikroprocesora Z8001 pokazany jest na Rysunku 2. Projektanci, jak widać, nie potrafili całkowicie oderwać się od poprzednich 8-bitowych konstrukcji i wybrali segmentowy model adresowania pamięci. Jest on nieco podobny do tego znanego z i8086, lecz bardziej uniwersalny. Ograniczenie bezpośredniego adresowania do 64 KiB pozwala na zmniejszenie długości operandów, a co za tym idzie - na skrócenie czasu przetwarzania instrukcji. Wprowadza jednak niejednorodności przy obsłudze większych bloków pamięci, a taką potrzebę w roku 1979 można już było bez trudu przewidzieć.
Wewnętrzna architektura Z8001 jest bardziej regularna od tej znanej z poprzednich konstrukcji Intela. Wyposażono ją dodatkowo w blok dekodujący instrukcje z wyprzedzeniem (ang. look-ahead instruction decoder). Zawiera blok 16 rejestrów 16-bitowych w większości ogólnego przeznaczenia. Rejestry R14/R15 są dedykowane jako wskaźnik stosu (segment i przesunięcie), rejestry R0..7 mogą być dostępne jako indywidualne rejestry 8-bitowe, czyli odpowiednio RL0..7 i RH0..7. Dodatkowym atutem jest możliwość agregacji rejestrów w 32-bitowe pary, np. RR2. Dostępny jest także tryb łączenia czterech kolejnych rejestrów w 64-bitowe pary, np. RQ12. Pary 64-bitowe są stosowane do przechowywania wyniku mnożenia dwóch 32-bitowych liczb lub wyniku ich dzielenia w formacie iloraz:reszta. Fakt, że pomimo posiadania 16-bitowej jednostki arytmetyczno-logicznej dostępne są działania na 32-bitowych operandach, zasługuje na podkreślenie.
Procesor może pracować w trybie bez segmentacji, oferując wtedy jednolite, 16-bitowe adresowanie. Ogranicza to przestrzeń adresową do 64 KiB, lecz przyspiesza wykonywanie instrukcji, szczególnie tych operujących na komórkach pamięci. Włączenia trybu pracy z segmentacją dokonuje się za pomocą ustawienia znacznika SEG.
W trybie z segmentacją 23-bitowy adres fizyczny powstaje przez złożenie 7-bitowego numeru segmentu i 16-bitowego adresu przesunięcia względem początku segmentu. Numer segmentu jest wyprowadzony bezpośrednio na zewnątrz mikroprocesora i może być wykorzystany wprost do adresowania 8 MiB pamięci. Przy wykorzystaniu zewnętrznego układu MMU Z8010 (ang. memory management unit - jednostka zarządzania pamięcią) numer segmentu może być wykorzystany do wybrania jednego ze zdefiniowanych uprzednio deskryptorów segmentu pamięci. MMU dokonuje procesu translacji 23-bitowego adresu logicznego na 24-bitowy adres fizyczny w oparciu o znajdującą się w nim tablicę 64 deskryptorów. Każdy z nich definiuje obszar jednego segmentu pamięci, jego typ, parametry dostępu i poziom uprzywilejowania.
W skład systemu z Z8001 może wchodzić więcej niż jeden układu MMU, co umożliwia zdefiniowanie więcej niż 64 deskryptorów. Dodatkowo Z8010 oferuje sprzętową kontrolę przepełnienia stosu i automatyczną kontrolę dostępu do pamięci z uwzględnieniem poziomu uprzywilejowania i charakteru tego dostępu (np. dostęp do segmentu kodu tylko do odczytu).
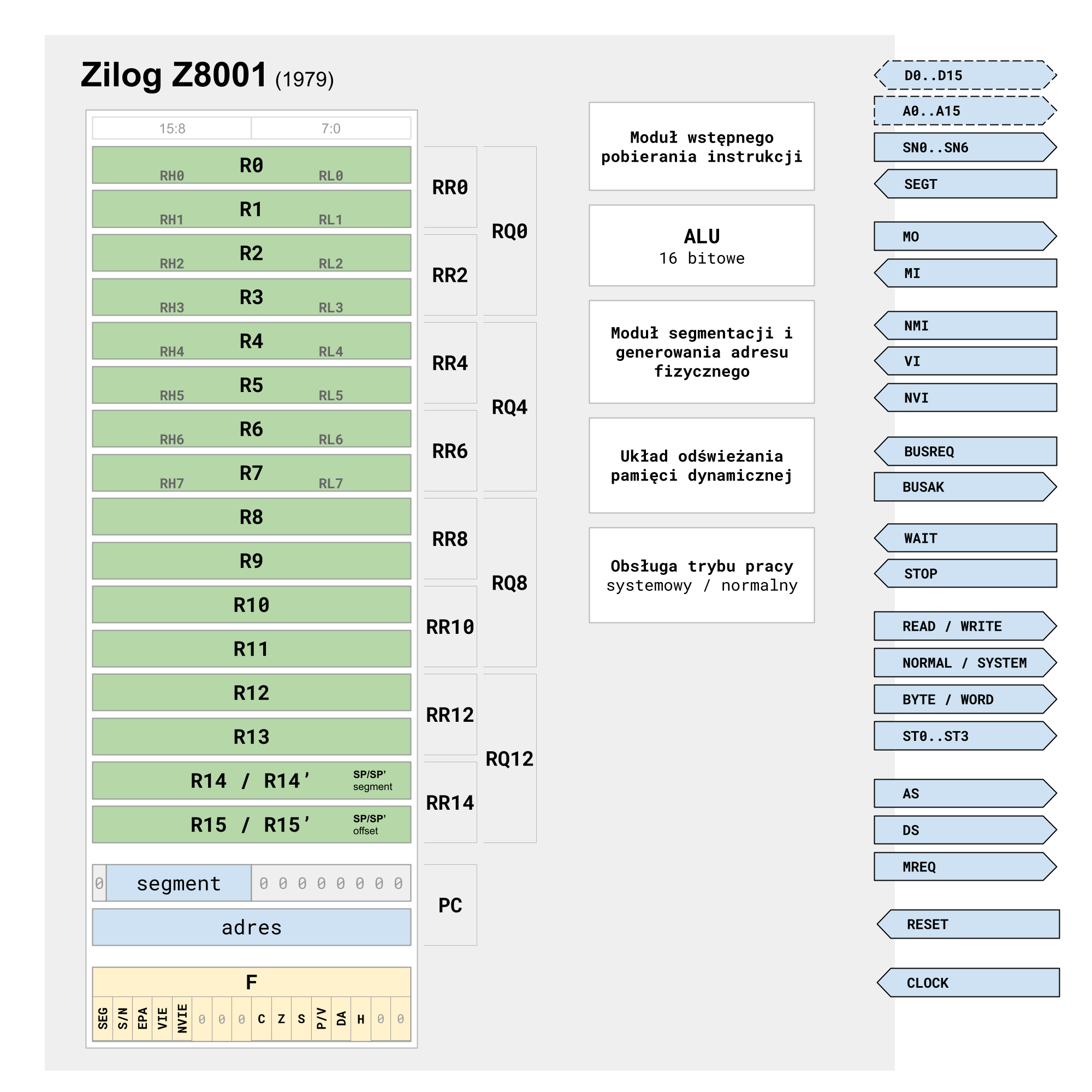 Rysunek 2. Schemat blokowy mikroprocesora Zilog Z8001
Rysunek 2. Schemat blokowy mikroprocesora Zilog Z8001
Zaimplementowanie odrębnego trybu użytkownika i trybu systemowego, wybieranego za pomocą znacznika S/N, ułatwia stosowanie Z8001 w systemach operacyjnych typu UNIX, które wymagają kontroli dostępu do systemowych funkcji i struktur danych. W trybie systemowym wszystkie instrukcje i dostęp do wszystkich zasobów jest dozwolony. W trybie użytkownika dostęp do układów wejścia/wyjścia i określonych obszarów pamięci oraz pewnych instrukcji jest zabroniony. Dodatkowo procesor w trybie chronionym ma osobny, systemowy wskaźnik stosu (R14’/R15’). Ma również dostęp do wskaźnika stosu trybu użytkownika za pomocą instrukcji LDCTL (ang. load control - ładuj dane kontrolne). Z poziomu użytkownika dostęp do systemowego wskaźnika stosu nie jest możliwy.
Z trybem chronionym wiąże się również mechanizm pułapek (ang. trap). W Z8001 występują następujące ich rodzaje:
- Extended Instruction - instrukcja rozszerzona; sygnalizuje, że kod instrukcji przeznaczony jest dla koprocesora, bardziej szczegółowe omówienie znajduje się poniżej.
- Privileged Instruction - próba wykonania instrukcji uprzywilejowanej w trybie normalnym.
- Addressing Violation (Segment Trap) - próba niedozwolonego dostępu do adresu (segmentu). Generowana przez aktywowanie wejściowego sygnału SEGT przez MMU (np. Z8010).
- System Call - wywołanie funkcji systemowej; standardowy sposób na przekazanie kontroli z poziomu kodu pracującego w trybie użytkownika do kodu systemu operacyjnego, pracującego w trybie systemowym.
Wzorem i8086 mikroprocesor firmy Zilog zawierał mechanizmy umożliwiające wykorzystywanie tzw. EPU (ang. extended processing unit - jednostka przetwarzania rozszerzonego, koprocesor), jak określono w dokumentacji dodatkową jednostkę przetwarzającą. Obecność EPU określał znacznik EPA, jeśli nie był ustawiony, oznaczało to brak fizycznego koprocesora i każda próba wykonania instrukcji rozszerzonej generowała wyjątek (ang. trap - pułapka). Schemat współpracy procesora głównego z koprocesorem jest podobny do tego opisanego dla i8086. Obliczanie adresu efektywnego operandu było zadaniem procesora głównego, koprocesor monitorował strumień instrukcji i wychwytywał oraz wykonywał tylko te przeznaczone dla siebie. EPU i CPU pracowały całkowicie asynchronicznie, wymuszenie wstrzymania CPU aż do zakończenia przetwarzania bieżącej instrukcji przez EPU realizowane było za pomocą sygnału wejściowego STOP mikroprocesora Z8001. Dostępne były cztery rodzaje instrukcji rozszerzonych:
- wewnętrzne instrukcje wykonywane przez EPU,
- przesyłanie danych pomiędzy EPU i pamięcią,
- przesyłanie danych pomiędzy EPU i CPU,
- przesyłanie danych między rejestrami znaczników EPU a rejestrami znaczników i słowem kontrolnym CPU. Stosowane między innymi do sprawdzania rezultatu wykonania instrukcji po stronie EPU i wykorzystania go w skoku warunkowym.
Stosowanie pułapki do przechwytywania instrukcji rozszerzonych jest wygodną metodą ich emulacji w przypadku braku fizycznego koprocesora. Ten sam kod może być wykonywany przez fizyczne EPU, jak i w trybie emulacji programowej. Zilog Z8001 zawierał również dedykowane instrukcje do komunikacji między-procesorowej, tzw. instrukcje Multi-Micro.
Mechanizm przerwań, który co do zasady jest podobny do mechanizmu pułapek, lecz w odróżnieniu od niego asynchroniczny, został zaimplementowany następująco:
NMI- przerwanie niemaskowalne, tę funkcję pełni również obsługa resetu sprzętowego (pin RESET), która ma osobny adres obsługi.NVI- przerwanie maskowalne, niewektoryzowane. 16-bitowe słowo identyfikujące rodzaj przerwania jest dostępne na stosie, jednak nie ma wpływu na adres procedury obsługi, który jest stały.VI- przerwanie maskowalne, wektoryzowane. 16-bitowe słowo identyfikujące rodzaj przerwania jest dostępne na stosie oraz jest wykorzystywane przez mikroprocesor do określenia adresu procedury obsługi (wektora) przerwania.
Sumaryczne przedstawienie podstawowych danych omawianego mikroprocesora znajduje się w poniższej tabeli.
| rok wprowadzenia do produkcji | 1979 |
| ilość tranzystorów | 17500 |
| częstotliwość taktowania | 6 MHz (cykl zegarowy: ~ 0.17 μs) |
| najkrótszy cykl instrukcji | 0.5 μs (3 cykle zegarowe) |
| indeks prędkości | 2 MIPS |
| dodawanie 64-bitowe | 26086 / s |
| efektywność architektury | 1491 |
| typ architektury | 16-bitowa, CISC |
| kolejność bajtów | big-endian |
| licznik programu | 7-bit segment : 16-bit offset |
| stos | 7-bit segment : 16-bit offset |
| rejestry ogólne | 14 x 16-bit |
| ALU | 16-bit ogólnego przeznaczenia |
| adresowanie pamięci | 8 MiB (23-bit adres), adresowanie segmentowe |
| adresowanie portów | 2 obszary po 64 KiB adresów we/wy każdy |
| przerwania | niemaskowalne, wektoryzowane, niewektoryzowane, system priorytetów |
| dzielenie i mnożenie liczb całkowitych | tak |
| tryby pracy | normalny/systemowy - segmentowany/niesegmentowany |
| praca z koprocesorem | tak |
| systemy wieloprocesorowe | tak |
Znaczniki:
SEG- tryb z segmentowaniemS/N- tryb systemowy / normalnyEPA- tryb rozszerzonej architekturyVIE- przerwania wektoryzowaneNVIE- przerwania niewektoryzowaneC- przeniesienieZ- zeroS- znakP/V- parzystość/przepełnienieDA- korekta dziesiętnaH- przeniesienie pomocnicze
Tryby adresowania:
- domyślne
- natychmiastowe
- rejestrowe
- bezpośrednie
- pośrednie rejestrowe
- indeksowane
- bazowe
- bazowe indeksowane
- blok danych
- względne
Zestaw instrukcji jest imponujący - zawiera instrukcje transferu blokowego LDIR z licznikiem słów, gdzie tak licznik, jak i rejestry zawierające adres źródłowy i docelowy mogą być wyspecyfikowane w instrukcji. Podobnie działają instrukcje porównywania i wyszukiwania blokowego, a także instrukcja TRIRB/TRDRB realizująca translacje ciągu bajtów w oparciu o 256-bajtową tabelę kodów. Jednak pomimo takiej różnorodności wiele instrukcji ma ściśle określone tryby adresowania operandów i w związku z tym, wskutek braku instrukcji blokowej, której operandem byłby rejestr (jak np. LODS/STOS w i8086), pętla naszego benchmarku musiała zostać zrealizowana w sposób klasyczny.
; Zilog Z8001
; dodawanie dwóch liczb 64-bitowych
; ARG0, ARG1 - etykiety buforów zawierających argumenty
; wynik zapisywany jest w ARG1, dane zorganizowane są w 16-bitowe słowa
; kolejność bajtów w słowie zgodna z wymaganą przez architekturę procesora
; słowa w buforze w kolejności od najmniej znaczącego
CLR R1 ; (7) zeruj rejestr przesunięcia
RESFLG C ; (7) zeruj znacznik przeniesienia
NST:
LD R2, ARG0(R1) ; (10) załaduj kolejne słowo argumentu 0
LD R3, ARG1(R1) ; (10) załaduj kolejne słowo argumentu 1
ADC R3, R2 ; (5) dodaj słowa
LD ARG1(R1), R3 ; (12) zapisz wynik do kolejnego słowa argumentu 1
INC R1, #2 ; (4) zwiększ przesunięcie o 2
CP R1, #8 ; (7) porównaj przesunięcie z rozmiarem argumentów
JR NE, NST ; (6) jeśli < 8 kontynuuj
Zliczając czasy wszystkich instrukcji, mamy: 14 + 4 x 54 = 230 cykli zegara. Czas wykonania wynosi więc około 38.3 μs, co daje 26086 dodawań na sekundę.
Mikroprocesor Zilog Z8001 oferuje znacznie więcej niż współczesny mu Intel 8086 i to przy użyciu znacznie mniejszej liczby tranzystorów w strukturze. Udało się tego dokonać dzięki odmiennej od konkurencji metodzie projektowania układu wykonawczego, realizującego na poziomie mikroarchitektury instrukcje procesora.
Zazwyczaj układ wykonawczy mikroprocesora oparty jest na tzw. mikrokodzie, który z kolej inicjuje wykonanie serii określonych sekwencji tzw. nanokodu. Podział ten i konwencja nazewnicza jest umowna, sprowadza się jednak do tego, że nanokod jest sekwencją wielobitowych słów, które bezpośrednio sterują poszczególnymi blokami mikroarchitektury procesora. Matryca bitowa określająca nanokod zajmuje stosunkowo dużo miejsca w układzie scalonym, dlatego metodą na zaoszczędzenie tego miejsca jest kodowanie w ten sposób tylko unikalnych sekwencji. Sekwencje nanokodu są grupowane i wywoływane przez mikrokod, którego komendy są już krótsze, a co za tym idzie całe sekwencje zajmują mniej miejsca. Oprócz oszczędności miejsca taka metoda jest znacznie wygodniejsza w fazie projektowania i umożliwia dokonywanie zmian praktycznie do ostatniej chwili przed oddaniem mikroprocesora do masowej produkcji. Alternatywą jest projektowanie klasycznej logiki opartej na bramkach logicznych, rejestrach i innych nisko-poziomowych blokach stosowanych układach mających tzw. strukturę nieregularną (ang. random logic). Układ logiczny wykonany jako struktura nieregularna wymaga zazwyczaj mniejszej ilości tranzystorów i jest szybszy, jego projektowanie natomiast jest zadaniem bardzo czasochłonnym, szczególnie przy układach VLSI (ang. very large scale of integration - bardzo duża skala integracji), jakimi są mikroprocesory. Projektanci firmy Zilog podjęli się tej tytanicznej pracy, by maksymalnie wykorzystać elementy półprzewodnikowe znajdujące się w strukturze mikroprocesora. Przyjęte przez nich rozwiązanie hybrydowe pozwoliło znacznie zredukować liczbę tranzystorów, a więc i cenę mikroprocesora. Jednak odbyło się to kosztem zmniejszenia elastyczności listy rozkazów pod względem dostępnych dla nich trybów adresowania operandów. Zmniejszeniu uległa tzw. ortogolnalność dla bardziej wyspecjalizowanych czy rzadziej wykorzystywanych instrukcji, co ogranicza możliwość ich stosowania w kodzie programu.
Motorola 68000
Projektanci i zarządzający firmą Motorola, inaczej niż ich koledzy z firmy Intel, rozpoznali nadchodzącą zmianę paradygmatu w tworzeniu oprogramowania. Aplikacje oszczędne, a wręcz ascetyczne, oparte na pracy w trybie tekstowym, miały definitywnie odejść w przeszłość. Proste, iteracyjne rozszerzanie istniejących konstrukcji, mających swoje korzenie w systemach wbudowanych komunikujących się przez terminal, miały zostać zastąpione dynamicznym, graficznym interfejsem użytkownika. To oznaczało konieczność przetwarzania znacznie większych porcji danych, znacznie szybciej i w znacznie bardziej wyrafinowany sposób. Niezbędne stało się projektowanie systemów komputerowych pod kątem oprogramowania i programistów, a nie głównie sprzętu, jak to było dotychczas.
W tym celu powołano projekt MACSS (ang. Motorola’s Advanced Computer System on Silicon), czyli w wolnym tłumaczeniu: zaawansowany system komputerowy firmy Motorola zaimplementowany w krzemie. Członkowie projektu mieli prawie całkowitą swobodę, był to tzw. green field, na którym mogli zaprojektować to, co chcieli, bez oglądania się na wcześniejsze konstrukcje. Celem był mikroprocesor mający sprostać wyzwaniom przyszłości, tak jak je rozumiano w połowie lat 70-tych XX wieku. Projektanci zdecydowali się na zachowanie zgodności z układami peryferyjnymi rodziny M6800 co nie ograniczało ich inwencji w kwestii architektury nowego mikroprocesora, a dawało znaczącą przewagę marketingową podczas rynkowego debiutu.
Pierwszą decyzją było wprowadzenie płaskiego (ang. flat), 32-bitowego adresowania, bez jakiejkolwiek segmentacji. W praktyce pociągnęło to za sobą konieczność zastosowania 32-bitowych rejestrów w celu wygodnej manipulacji na adresach. Wewnętrzna architektura procesora M68000 musiała być w dużej części 32-bitowa. Ta decyzja stała się jednym z filarów jej ogromnego sukcesu. Poglądowy schemat mikroprocesora M68000 zaprezentowano na Rysunku 3.
 Rysunek 3. Schemat blokowy mikroprocesora Motorola 68000
Rysunek 3. Schemat blokowy mikroprocesora Motorola 68000
Na zewnątrz obudowy wyprowadzono tylko 24-bity adresu, lecz model programowy i mikroarchitektura były gotowe na kolejne modele, w których miano udostępnić pełne 32 bity. Dawało to już na starcie możliwość bezpośredniego zaadresowania 16 MiB pamięci z perspektywą rozszerzenia do pełnych 4 GiB w kolejnych modelach rodziny M68000. Z powodu decyzji o zgodności z peryferiami serii M6800 najmłodszy bit adresu został zastąpiony dwoma osobnymi sygnałami LDS/UDS, które służyły do wybierania mniej lub bardziej znaczącego bajtu na 16-bitowej szynie danych. W celu przyspieszenia operacji wyliczania adresu efektywnego zastosowano dwie dodatkowe, dedykowane 16-bitowe jednostki arytmetyczne. W ten sposób główne ALU nie musiało być wykorzystywane w tym celu, a proces wyliczania adresu mógł przebiegać równolegle z wykonywaniem operacji arytmetyczno-logicznych wynikających z instrukcji. Dodatkowe jednostki arytmetyczne można było wykorzystać wprost np. za pomocą instrukcji LEA (ang. load effective address - ładuj adres efektywny), co pozwalało zachować wprost wynik obliczeń w rejestrze.
Zaprojektowano kolejkę pobierania wstępnego o długości dwóch słów 16-bitowych. Układ pobierania z wyprzedzeniem był odpowiedzialny za załadowanie do niej kolejnej instrukcji. Jeśli możliwe było rozgałęzienie, w przypadku instrukcji warunkowych, pobrane mogły być instrukcje dla obu wariantów. Bufor miał 2 x 16 bitów, ponieważ długość każdej instrukcji, nie licząc operandów, to właśnie 16 bitów.
Blok rejestrów składał się z ośmiu 32-bitowych rejestrów danych D0..7, ogólnego przeznaczenia, oraz ośmiu rejestrów adresowych A0..7, również 32-bitowych. Z nich A7 był dedykowany jako wskaźnik stosu. Rozróżnienie pomiędzy rejestrami danych i adresowymi miało jeden ważny powód. Operacje arytmetyczne na rejestrach danych ustawiają wskaźniki, jak np. wskaźnik przepełnienia, natomiast operacje na rejestrach adresowych nie zmieniają ich. Dzięki temu można łatwo przeplatać operacje arytmetyczne na rejestrach adresowych z operacjami na danych, bez konieczności każdorazowego zapisywania i odtwarzania znaczników. Ma to zastosowanie np. w operacjach wielobajtowego dodawania, które wymaga zachowania znacznika przeniesienia. Rejestry danych mogą dodatkowo być wykorzystywane jako 8 czy 16-bitowe.
Jedną z ciekawostek było wprowadzenie znacznika X (ang. extension - rozszerzenie), który podczas operacji arytmetycznych czy logicznych był ustawiany jednocześnie ze znacznikiem C (ang. carry - przeniesienie). Znacznik C jest wykorzystywany przez instrukcje skoków warunkowych, natomiast znacznik X jest używany jako przeniesienie w operacjach dodawania czy odejmowania, efektywnie rozszerzając operandy o jeden bit. Dodatkową innowacją było zastosowanie dwukierunkowego sygnału RESET, który mógł być wykorzystany przez procesor do resetowania układów zewnętrznych instrukcją.. RESET.
Mikroprocesor oferował dwa tryby wykonywania programu: tryb użytkownika i tryb nadzorcy (ang. supervisor). Tryb pracy określa wartość wskaźnika S w systemowej części rejestru CCR (ang. conditional code register - rejestr kodów warunków) lub też SR (ang.system register - rejestr systemowy). W trybie nadzorcy dostępny był osobny wskaźnik stosu jako alternatywny rejestr A7’, określany również jako SSP (ang. system stack pointer - systemowy wskaźnik stosu) w odróżnieniu od A7, czyli USP (ang. user stack pointer - wskaźnik stosu użytkownika).
Tryb pracy uprzywilejowanej, czyli nadzorcy, jest trybem, w którym możliwe jest wykonanie każdej instrukcji i dostęp do każdego zasobu. W trybie użytkownika niektóre zasoby, jak np. systemowa część rejestru znaczników, gdzie znajduje się bit S, nie jest dostępna. Przełączenie trybu z użytkownika na tryb nadzorcy możliwe jest przez zgłoszenie wyjątku (pułapki lub przerwania). Pierwsza wersja M68000 nie wspierała ochrony obszarów pamięci (ang. memory protection) bez zewnętrznego układu zarządzającego dostępem (MMU). W celu wykorzystania M68000 w systemach wielodostępnych typu UNIX zewnętrzny układ MMU zapewniający ochronę pamięci oraz translację adresów logicznych na fizyczne był niezbędny, a przynajmniej wysoce pożądany.
System przerwań bazuje na 3-bitowym identyfikatorze priorytetu, gdzie wartość 0 oznacza brak przerwania, a 7 przerwanie niemaskowalne (odpowiednik NMI w innych systemach). Przerwanie o priorytecie wyższym może przerwać procedurę obsługi przerwania o priorytecie niższym. Konsekwentnie program główny, pracujący na poziomie 0, może zostać przerwany przez każdy wyższy priorytet.
W systemach wieloprocesorowych instrukcja TAS (ang. test and set - sprawdź i ustaw) stanowiła podstawę implementacji semaforów zapewniających wyłączny dostęp do współdzielonych zasobów.
Skrócona specyfikacja mikroprocesora podana jest w poniższej tabeli.
| rok wprowadzenia do produkcji | 1979 |
| ilość tranzystorów | 68000 |
| częstotliwość taktowania | 8 MHz (cykl zegarowy: 0.125 μs) |
| najkrótszy cykl instrukcji | 0.5 μs (4 cykle zegarowe) |
| indeks prędkości | 2 MIPS |
| dodawanie 64-bitowe | 63492 / s |
| efektywność architektury | 934 |
| typ architektury | 16/32-bit, CISC |
| kolejność bajtów | big-endian |
| licznik programu | 32-bit (24-bit zew) |
| stos | 32-bit (24-bit zew) użytkownika i nadzorcy |
| rejestry | 14 x 32-bit ogólnego przeznaczenia |
| ALU ogólnego przeznaczenia | 1 x 16-bit |
| ALU do wyliczania adresu | 2 x 16-bit |
| adresowanie pamięci | 16 MiB jednolite (23-bit adresu + 2-bit wyboru bajtu) |
| adresowanie portów | mapowane w obszarze pamięci |
| przerwania | priorytetowe o 7 poziomach, najwyższy niemaskowalny |
| dzielenie i mnożenie liczb całkowitych | tak |
| tryby pracy | nadzorcy/użytkownika |
| praca z koprocesorem | tak |
| systemy wieloprocesorowe | tak |
Znaczniki:
T– tryb śledzeniaS– tryb nadzorcyI– maska przerwań (3 bitowa)X– bit rozszerzeniaN– znakZ– zeroV– przepełnienieC– przeniesienie
Tryby adresowania:
- domyślne
- natychmiastowe
- bezpośrednie
- rejestrowe
- pośrednie rejestrowe (z predekrementacją, postinkrementacją, indeksowaniem, przesunięciem)
- względne (z indeksem, przesunięciem)
Tym, co najbardziej fascynuje w architekturze Motoroli 68000, jest zestaw instrukcji i ortogonalność względem trybów adresowania. Projektanci słusznie uznali instrukcję przesłania (transferu) danych między dwoma lokalizacjami za podstawowy element składowy programu. Rozwijając konsekwentnie tę ideę, wyeliminowali nawet tak powszechnie występujące instrukcje jak operacje na stosie, czyli PUSH i POP, które stały się przypadkiem szczególnym użycia instrukcji MOVE. Nie istnieją również osobne instrukcje inkrementacji i dekrementacji, ponieważ w uniwersalny sposób realizują te funkcje warianty instrukcji ADD i SUB.
Poniżej zaprezentowano na przykładach kilka charakterystycznych dla asemblera M68000 konstrukcji:
MOVEM.L D0/D4-D7/A4/A5,40(A6)
Prześlij (MOVE) wiele (M) słów 32-bitowych (.L) kolejno z rejestrów: D0, D4, D5, D6, D7, A4, A5 do pamięci, począwszy od adresu będącego sumą wartości rejestru A6 i przesunięcia 40. To wszystko w jednej instrukcji! Uwagę zwraca również kolejność operandów, inna niż w większości procesorów, określająca najpierw źródło, a później przeznaczenie przesyłanych danych.
MOVEQ 123,D2
Prześlij (MOVE) szybko (Q) 8-bitową wartość natychmiastową do rejestru D0. Wartość jest częścią 16-bitowej instrukcji, więc czas wykonania jest najkrótszy z możliwych i wynosi 4 cykle zegara.
MOVE.W (A5)+,D1
Prześlij (MOVE) szybko (Q) daną 16-bitową (.W) spod adresu zawartego w A5 do rejestru D1. Następnie zwiększ A5 o 2 (post-inkrementacja), ponieważ rozmiar przesyłanych danych to 2 bajty.
MOVE.L D1,-(A7)
Odpowiednik instrukcji typu PUSH. Odejmij od rejestru A7 wartość 4, a następnie prześlij (MOVE) słowo 32-bitowe (.L) z rejestru D1 pod adres znajdujący się w rejestrze A7, czyli na wierzchołek stosu. Wartość pre-dekrementacji wynika z rozmiaru przesyłanej porcji danych w bajtach.
ADDX.L -(A2),-(A5)
Zmniejsz o 4 rejestry A2 i A5, następnie dodaj (ADD) z uwzględnieniem rozszerzenia/przeniesienia (X) 32-bitową (.L) zawartość pamięci pod adresem A2 do zawartości pamięci pod adresem A5. Wynik zapisz w pamięci pod adresem A5.
ADDQ.B #1,D4
Odpowiednik instrukcji typu INC. Dodaj (ADD) szybko (Q) bajt (.B) o wartości 1 do rejestru D4. Operand jest zawarty w kodzie instrukcji, która w całości mieści się na 16-bitach, jej czas wykonania to 4 cykle zegara, czyli najkrótszy z możliwych. W ten sposób można dodawać lub odejmować (SUBQ) wartości od 1 do 8.
Siłą tego modelu programowego jest jego regularność i uniwersalizm. Jest intuicyjny, łatwy do nauczenia się i poprawnego stosowania. Nie bazuje na wielości wyspecjalizowanych rozwiązań, lecz na swobodnym składaniu instrukcji i trybów adresowania w logiczną i zwartą w zapisie operację. Poniżej znajduje się kod standardowego, 64-bitowego dodawania:
; Motorola 68000
; dodawanie dwóch liczb 64-bitowych
; ARG0, ARG1 - etykiety buforów zawierających argumenty
; wynik zapisywany jest w ARG1, dane zorganizowane są w 32-bitowe słowa
; kolejność bajtów w słowie zgodna z wymaganą przez architekturę procesora,
; słowa w buforze w kolejności od najmniej znaczącego
LEA ARG0, A0 ; (8) ładuj adres pierwszego argumentu do A0
LEA ARG1, A1 ; (8) ładuj adres drugiego argumentu do A1
MOVEQ #1, D1 ; (4) ustaw licznik pętli
ANDI #F6, CCR ; (20) zeruj znacznik przeniesienia (C i X)
NST:
MOVE.L (A0)+, D0 ; (12) pobierz kolejne długie słowo z ARG0
ADDX.L D0, (A1)+ ; (20) dodaj do kolejnego długiego słowa z ARG1
DBRA D1, NST ; (10) kontynuuj dla kolejnego słowa
Zliczając czasy wszystkich instrukcji, mamy: 40 + 2 x 42 + 2 = 126 cykli zegara. Czas wykonania wynosi 15.75 μs, co daje 63492 dodawań na sekundę.
Lista instrukcji może zostać względnie łatwo rozszerzona za pomocą rozkazów o najstarszych bitach kodu operacji równych 1010 i 1111. Próba wykonania któregokolwiek z nich skutkuje wywołaniem pułapki line-1010-emulator lub line-1111-emulator i odpowiedniej procedury obsługi. Rozkazy z pierwszej grupy są zdefiniowane jako operacje zmiennoprzecinkowe i w podstawowym modelu 68000 muszą być emulowane. Druga grupa jest zarezerwowana do zastosowania w przyszłości.
Po tym krótkim opisie widać, że architektura mikroprocesora Motorola 68000 i całej późniejszej rodziny wyróżnia się na tle poprzednio omawianych konstrukcji. Jest przemyślana od początku do końca i zaprojektowana pod kątem potrzeb programisty i oprogramowania. Do dziś stanowi przykład nowatorskiego podejścia, które zakończyło się spektakularnym sukcesem.
Intel 80286
Architektura x86 zapoczątkowana przez mikroprocesor Intel 8086 zyskała bardzo dużą popularność dzięki zastosowaniu jej w komputerach klasy IBM XT. W obliczu konkurencyjnych konstrukcji firm Zilog, a przede wszystkim Motorola, Intel musiał zaprezentować bardziej zaawansowany projekt. Intel 80286 oferował bardzo wiele usprawnień i rozszerzeń względem swojego prekursora.
Przede wszystkim mikroarchitektura została przeprojektowana, bloki funkcjonalne BU (ang. bus unit - jednostka szyny), AU (ang. address unit - jednostka adresowania), IU (ang. instruction unit - jednostka rozkazów) i EU (ang. execution unit - jednostka wykonawcza) zostały wyodrębnione i połączone ze sobą w „bardziej luźny” sposób za pomocą buforów. Pozwoliło to na stosowanie kolejkowania na większą skalę i wykonywania zadań równolegle przez kilka modułów naraz. Znaczne zwiększenie wydajności uzyskano przez wbudowanie dedykowanej jednostki obliczeniowej do generowania adresów oraz wyprowadzeniu szyny adresowej i danych niezależnie, bez multipleksowania. Układ mnożący i dzielący liczby całkowite został częściowo zaimplementowany sprzętowo, co zmniejszyło czas wykonywania tych instrukcji. Oprócz obecnego już w poprzednich modelach bufora pobierania instrukcji z wyprzedzeniem został w i80286 dodany bufor zdekodowanych już instrukcji, co pozwalało zrównoleglić fazę dekodowania z fazą wykonywania. Poglądowy schemat wewnętrzny mikroprocesora zaprezentowano na Rysunku 4.
Obsługa kodu przeznaczonego dla koprocesora została wzbogacona o możliwość generowania pułapki/wyjątku przy napotkaniu dedykowanego dla niego rozkazu. Jeśli znacznik EM był ustawiony, każdy taki rozkaz mógł zostać emulowany przez procedurę obsługi wyjątku w sposób całkowicie transparentny dla oprogramowania. W systemach bez zainstalowanego, fizycznego, koprocesora było to bardzo wygodne rozwiązanie.
Najbardziej istotną zmianą było dodanie możliwości pracy w trybie chronionym oraz dosyć rozbudowanego jak na owe czasu mechanizmu zarządzania dostępem do pamięci MMU (ang. memory management unit - jednostka zarządzania pamięcią). Według pierwotnych założeń firmy Intel mikroprocesor ten nie był projektowany do wykorzystania w komputerach osobistych, a raczej w systemach wielodostępnych (ang. multi-user), wielozadaniowych czy zaawansowanych centralach telekomunikacyjnych czy tzw. centralach abonenckich. Ostatecznie został jednak wykorzystany jako procesor w komputerach osobistych drugiej generacji firmy IBM czyli IBM AT.
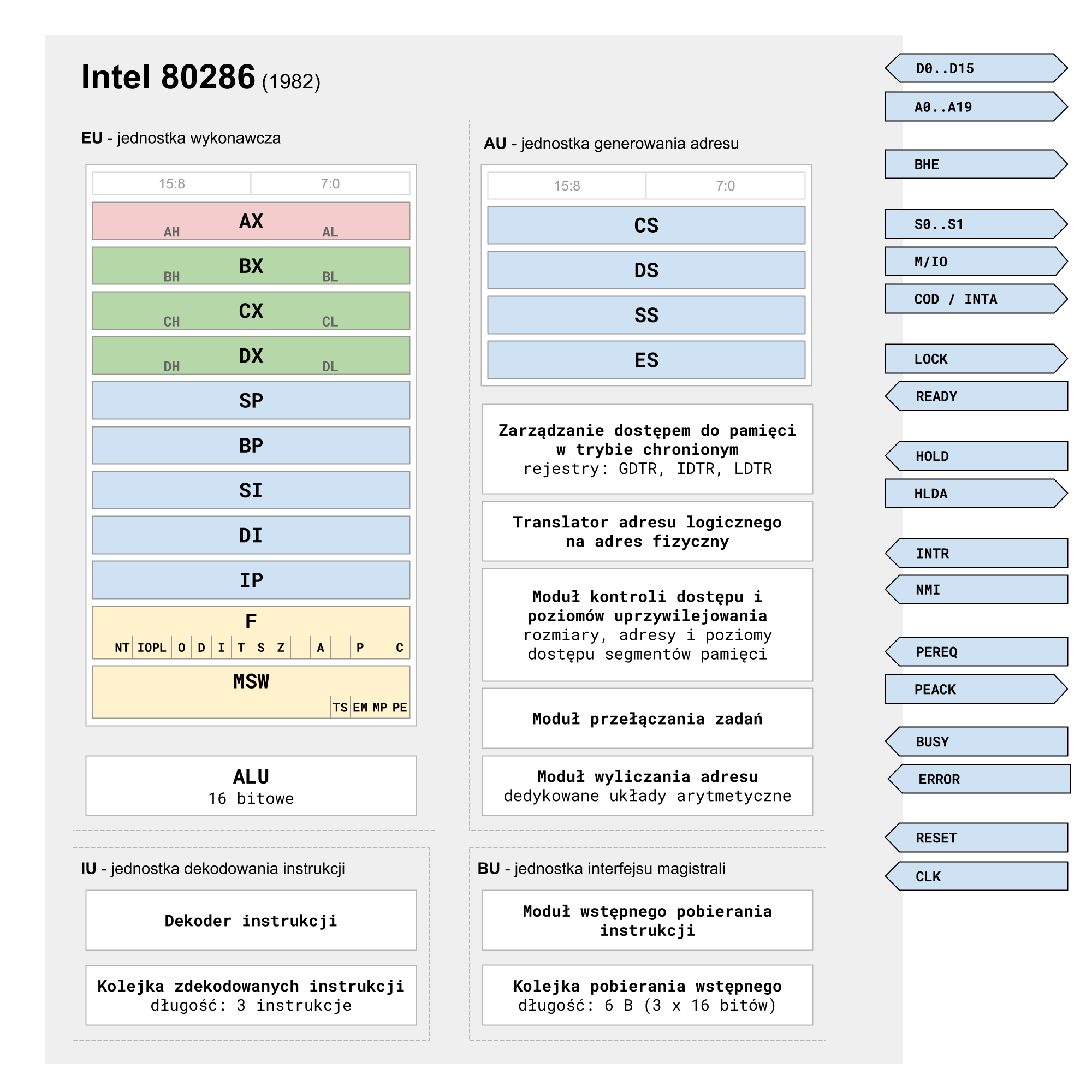 Rysunek 4. Schemat blokowy mikroprocesora Intel 80286
Rysunek 4. Schemat blokowy mikroprocesora Intel 80286
Mikroprocesor Intel 80286 (znany również jako iAPX286) mógł pracować w dwóch trybach: rzeczywistym i chronionym. W trybie rzeczywistym zachowywał się jak klasyczny 8086 i był to domyślny tryb, w którym uruchamiał się po resecie. Magistrala adresowa w 80286 była 24-bitowa, co pozwalało na zaadresowanie 16 MiB pamięci, natomiast tryb rzeczywisty oferował tylko 1 MiB. W trybie rzeczywistym adres efektywny wyliczany był jako suma adresu segmentu i przesunięcia, co dawało 20-bitowy adres. Maksymalny adres segmentu to 0xFFFF0 (0xFFFF x 16), co po dodaniu 16-bitowego offsetu wykracza poza jeden megabajt. Poprzednie procesory miały tylko 20-bitowy adres, nie mogły więc wykorzystać tego triku, który w i80286 pozwalał na udostępnienie tzw. HMA (ang. high memory area - obszar pamięci wysokiej), co dawało nieco miejsca na krótsze programy, najczęściej sterowniki, w systemie MS-DOS.
Swoje pełne możliwości mikroprocesor pokazywał dopiero po przejściu w tryb chroniony. co możliwe było przez ustawienie bitu znacznika PE w rejestrze MSW (ang. machine status word - słowo stanu procesora). Ciekawostką jest, że raz ustawiony bit PE nie mógł zostać skasowany, więc powrót do trybu rzeczywistego był możliwy tylko poprzez reset. Ten mankament został usunięty w modelu i80386.
W trybie chronionym dostępne były mechanizmy zarządzania, wirtualizacji adresu fizycznego i ochrony obszarów pamięci. Adres pamięci w dalszym ciągu reprezentowany był jako 16-bitowe przesunięcie (ang. offset) i 16-bitowy segment, lecz tym razem nie był to adres segmentu, lecz tzw. selektor, czyli identyfikator segmentu w tablicy deskryptorów. Do określenia konkretnego deskryptora wykorzystanych jest 13-bitów, co daje 8192 deskryptory, dodatkowo bit TI określa, czy deskryptor ma znajdować się w tablicy GDT (ang. global descriptor table - globalna tablica deskryptorów), czy LDT (ang. local descriptor table - lokalna tablica deskryptorów), osobnej dla każdego zadania (ang. task). Pozostałe 2 bity RPL określają żądany poziom dostępu (ang. requested privilege level), który jest porównywany z poziomem uprzywilejowania segmentu. Już na tym etapie widać, że system operacyjny czy inny program nadzorujący może mieć swoją mapę pamięci zdefiniowaną w GDT, a poszczególne programy mniej uprzywilejowane mogą mieć osobne przestrzenie adresowe zdefiniowane w ich własnych LDT. Położenie każdej z lokalnych tablic musi zostać uprzednio zdefiniowane w tablicy globalnej - daje to kontrolę nad definiowaniem wszystkich przestrzeni adresowych procesowi nadrzędnemu, mającemu uprzywilejowany dostęp do tablicy globalnej. Adres tablicy globalnej zawiera rejestr specjalny GDTR, a lokalnej dla danego zadania LDTR.
Szczegółowy opis funkcjonalności MMU dla trybu chronionego znacznie wykracza poza zakres tego artykułu, z konieczności podane zostaną więc syntetycznie tylko najważniejsze informacje. Struktura deskryptora ma długość 8 bajtów i zawiera następujące informacje:
- rozmiar (16 bitów) - określa rozmiar segmentu od 1 B do 64 KiB.
- adres początkowy (24 bity) - fizyczny adres w 16 MiB przestrzeni.
- dostęp (8 bitów) - określa rodzaj segmentu (kodu, danych, stosu), tryb dostępu (tylko do odczytu, możliwość wykonywania kodu, odczyt zapis itd.), dostępność w pamięci fizycznej i znacznik, czy segment był wcześniej wykorzystywany (przydatne przy implementacji pamięci wirtualnej). A także określenie, czy segment jest prawidłowy i dostępny, czy też nieprawidłowy (ang. invalid). Zawiera również poziom dostępu z zakresu 0..3, który porównywany jest z poziomem uprzywilejowania kodu, który żąda dostępu. Wynik porównania określa, czy dostęp może być przyznany.
Adresy tablic deskryptorów oraz wyliczone adresy bazowe i rozmiary oparte na danych z deskryptorów są umieszczane w ukrytych rejestrach mikroprocesora przyporządkowanych do każdego z rejestrów segmentowych (dla każdego zadania), co znacznie przyspiesza wyliczanie adresów efektywnych. Jest to swego rodzaje pamięc podręczna (ang. cache) jednostki MMU.
Za pomocą deskryptorów realizuje się także przekazanie sterowania do kodu o wyższym poziomie uprzywilejowania. W ten sposób implementuje się np. wywołania procedur systemu operacyjnego. Tego rodzaju deskryptory nazywa się bramkami (ang. gates) - dostępne są bramki wywołań procedur, przerwań, przełączania zadań i pułapek (ang. trap). Kolejną funkcjonalnością trybu chronionego jest efektywne przełączanie między zadaniami (ang. task switching). Każde zadanie ma swój oddzielny segment stanu TSS (ang. task state segment). Jest to 22-bajtowa struktura zawierająca:
- zawartość wszystkich rejestrów procesora dostępnych dla zadania,
- zawartość rejestru znaczników,
- selektor definiujący lokalną tablicę deskryptorów (LDT),
- wskaźniki stosu dla poziomów uprzywilejowania 0..2,
- wskaźnik do TSS poprzedniego zadania. Może być wykorzystany do zrestartowania poprzedniego zadania, jeśli aktualne, „zagnieżdżone” zadanie zostanie zakończone.
Część segmentu TSS, jak adres LDT czy początkowy adres stosu, jest stała. Pozostałe dane, jak np. wartości rejestrów czy znaczników, mogą oczywiście ulegać zmianom. Przełączenie zadania może zajść przez wywołanie przerwania czy bezpośredni skok do podprogramu będącego w innym segmencie TSS, a także powrót z przerwania lub podprogramu.
Pobieżny opis możliwości trybu chronionego procesora Intel 80286 daje pojęcie o elastyczności i poziomie zaawansowania jego MMU w porównaniu do poprzednio opisanych mikroprocesorów. To podejście zostanie jeszcze udoskonalone w następnym modelu Intel 80386. Najważniejsze informacje o omawianym mikroprocesorze zebrano w poniższej tabeli.
| rok wprowadzenia do produkcji | 1982 |
| ilość tranzystorów | 134000 |
| częstotliwość taktowania | 8 MHz (cykl zegarowy: 0.125 μs) |
| najkrótszy cykl instrukcji | 0.25 μs (2 cykle zegarowe) |
| indeks prędkości | 4 MIPS |
| dodawanie 64-bitowe | 81633 / s |
| efektywność architektury | 609 |
| typ architektury | 16-bitowa, CISC |
| kolejność bajtów | little-endian |
| licznik programu | 16-bit seg. kodu : 16-bit offset |
| stos | 16-bit seg. stosu : 16-bit offset |
| rejestry ogólnego przeznaczenia | 7 x 16-bit |
| rejestry segmentowe | 4 x 16-bit |
| ALU ogólnego przeznaczenia | 16-bit |
| ALU do obliczania adresu | tak |
| adresowanie pamięci | 16 MiB (24-bitowy adres), adresowanie segmentowane |
| adresowanie portów | 64 KiB portów wejścia/wyjścia |
| przerwania | sprzęt. (nie)maskowalne, programowe maskowalne, priorytety, razem 256 rodzajów |
| dzielenie i mnożenie liczb całkowitych | tak |
| tryby pracy | rzeczywisty/chroniony |
| praca z koprocesorem | tak |
| systemy wieloprocesorowe | tak |
Rejestr znaczników:
O- przepełnienieD- kierunek dla operacji łańcuchowychI- maska przerwańT- pułapka przy pracy krokowejS- znakZ- zeroA- przeniesienie pomocniczeP- parzystośćC- przeniesienieIOPL- priorytet operacji we/wyNT- zadanie zagnieżdżone
Rejestr słowa stanu (MSW):
TS- kontekst zadania został zmienionyEM- emulacja instrukcji rozszerzonychMP- monitorowanie instrukcji rozszerzonychPE- tryb chroniony
Tryby adresowania:
- domyślne
- natychmiastowe
- rejestrowe
- bezpośrednie
- pośrednie rejestrowe (z przesunięciem)
- bazowe (z przesunięciem)
- indeksowane (z przesunięciem)
- bazowe indeksowane (z przesunięciem)
- blok danych
- względne
Kod naszego standardowego benchmarku jest identyczny jak ten dla procesora Intel 8086, zmianie uległy natomiast czasy wykonania. Wskutek przebudowy i optymalizacji mikroarchitektury, szczególnie przez dodanie dedykowanej jednostki arytmetycznej do obliczania adresów i zastosowania pipeliningu, widać tutaj bardzo istotną poprawę.
; Intel 80286 (iAPX 286)
; dodawanie dwóch liczb 64-bitowych
; ARG0, ARG1 - etykiety buforów zawierających argumenty
; wynik zapisywany jest w ARG1, dane zorganizowane są w 16-bitowe słowa
; kolejność bajtów w słowie zgodna z wymaganą przez architekturę procesora
MOV SI, offset ARG0 ; (2) ładuj adres argumentu 0 do SI
MOV DI, offset ARG1 ; (2) ładuj adres argumentu 1 do DI
MOV CX, 4 ; (2) ustaw licznik słów
CLD ; (2) ustaw znacznik kierunku na inkrementację
CLC ; (2) zeruj znacznik przeniesienia
NST:
LODSW ; (5) ładuj blokowo kolejne słowo ARG0 do AX
ADC AX,[DI] ; (7) dodaj kolejne słowo z ARG1 do AX
STOSW ; (3) zapisz blokowo AX do kolejnego słowa ARG1
LOOP NST ; (8) kontynuuj dla następnego słowa
Sumując czasy wykonania, dostajemy: 10 + 4 x 23 - 4 (ostatni skok warunkowy nie zachodzi, więc zajmuje mniej cykli) = 98 cykli zegara. Czas wykonania wynosi więc 12.25 μs, co daje 81633 dodawań na sekundę. Liczba dodawań jest najwyższa z wszystkich opisanych mikroprocesorów, jednak wielkość współczynnika efektywności architektury może rozczarowywać. Jest to spowodowane tym, że tak prosta procedura, jak dodawanie wielobajtowe, nie wymaga rozbudowanych jednostek zarządzania pamięcią czy mechanizmu przełączania zadań. Do każdego pracy należy dobrać odpowiednie narzędzie i w tym przypadku widać to bardzo wyraźnie. Prowadzi to nieuchronnie do pytania, czy w każdym przypadku potrzebny jest wielozadaniowy system operacyjny oparty o wyrafinowany procesor ze sprzętową ochroną pamięci i wirtualizacją? Odpowiedź pozostawiam czytelnikowi, a kolejna omawiana konstrukcja zaprezentuje zupełnie odmienne podejście.
WDC 65C816
Firma Western Design Center, czyli WDC, została założona przez Billa Menscha, członka zespołu projektantów mikroprocesora Motorola 6800, a później MOS 6502 już pod szyldem MOS Technology. Pomimo początkowych trudności WDC przebiła się ze swoim pierwszym produktem, energooszczędną wersją MOS 6502 wykonaną w technologii CMOS. Kolejnym udanym produktem, z którego firma WDC jest do dziś chyba najbardziej znana, był właśnie omawiany WDC 65C816, czyli 16-bitowy mikroprocesor zgodny na poziomie kodu maszynowego z 6502, a jednocześnie oferujący w trybie „natywnym” znacznie rozszerzone możliwości. Nazwa 65816 nawiązywała do rdzenia „65”, oznaczającego kompatybilność z 6502, oraz „8/16”, czyli dostępne tryby 8 i 16-bitowe, „C” oznaczało technologię CMOS. W czasie kiedy WDC 65C816 wchodził na rynek, trend ku tworzeniu coraz bardziej wyrafinowanych procesorów był już wyraźny, lecz WDC postanowiło pójść własną drogą i zaproponować lepszą i szybszą konstrukcję zaprojektowaną w „starym stylu”. Uproszczony schemat blokowy WDC 65C816 zaprezentowano na Rysunku 5.
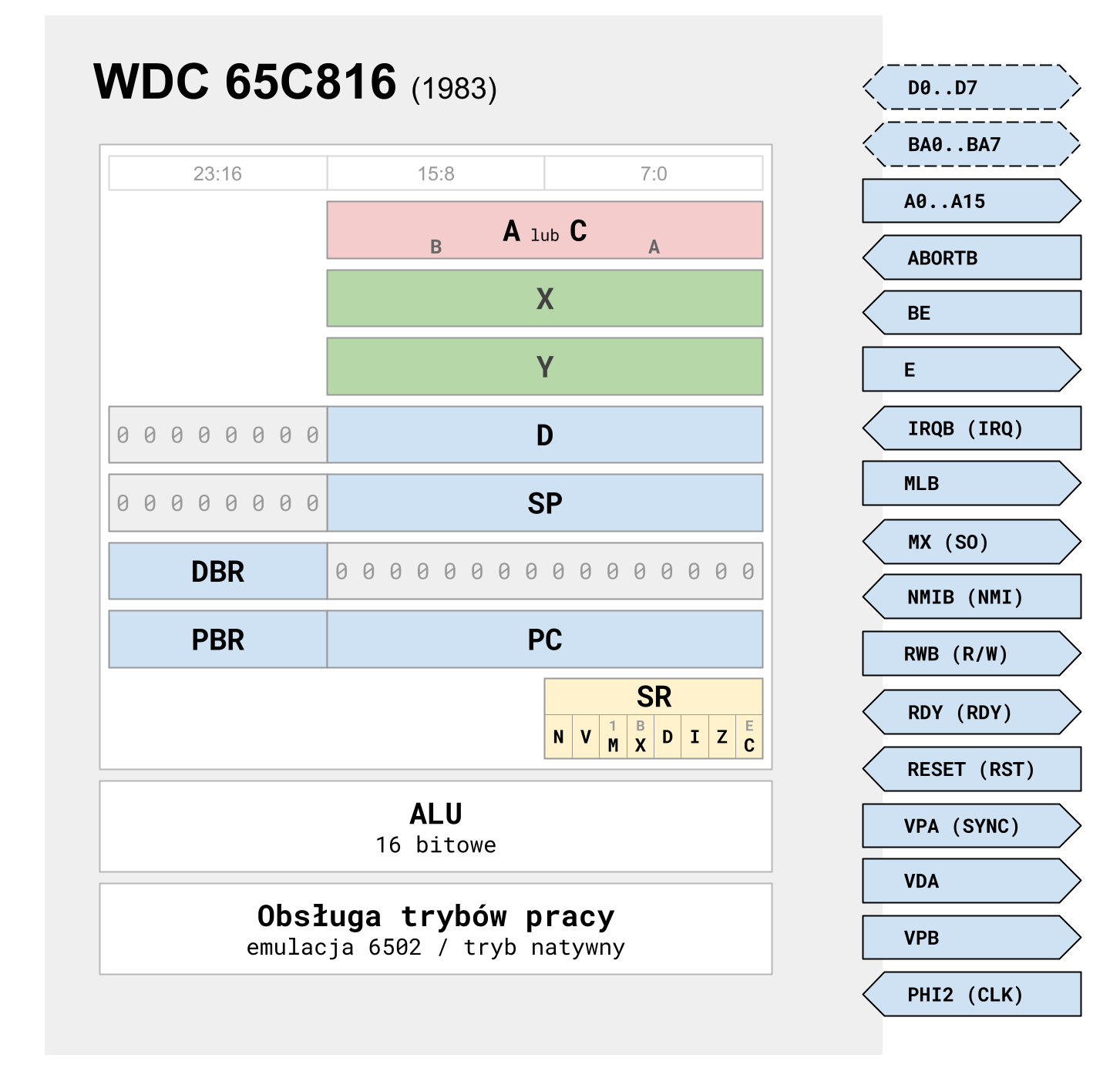 Rysunek 5. Schemat blokowy mikroprocesora WDC 65C816
Rysunek 5. Schemat blokowy mikroprocesora WDC 65C816
Przede wszystkim konstrukcja jest w pełni statyczna, wykonana w procesie CMOS, charakteryzująca się znacznie mniejszym poborem prądu niż oryginalne 6502 oraz możliwością obniżenia taktowania aż do zatrzymania zegara, bez ryzyka utraty danych z wewnętrznych rejestrów. Pełna zgodność programowa, na poziomie kodu maszynowego, dawała dostęp do ogromnej biblioteki kodu stworzonego dla 6502. Wprowadzono nawet specjalną wersję 65C802, która była zgodna z 6502 na poziomie wyprowadzeń i mogła być bezpośrednim zamiennikiem. Pociągnęło to za sobą ograniczenia w możliwościach adresowania pamięci i ostatecznie spowodowało mniejszą popularność tego mikroprocesora. W dalszej części artykułu omówiona zostanie tylko wersja 16-bitowa.
W trybie natywnym, który jest domyślnym trybem pracy mikroprocesora, mamy do dyspozycji 16-bitowy akumulator, złożony logicznie z dwóch 8-bitowych części, do których można uzyskać niezależny dostęp np. dzięki nowej instrukcji XBA. Akumulator i wszystkie operacje odczytu i zapisu z nim związane mogą być 8 lub 16-bitowe. Określa to stan znacznika M, czyli bitu trybu pracy akumulatora (ang. accumulator select bit). Z jednej strony daje to elastyczność i pewien wzrost szybkości wykonywania instrukcji, z drugiej wymaga każdorazowego ustawiania bądź zerowania odpowiedniego bitu w rejestrze znaczników. Lepszym rozwiązaniem byłoby wprowadzenie osobnych instrukcji dla operandów 8 i 16-bitowych. Względy związane ze zgodnością na poziomie kodu maszynowego i wzrost komplikacji rdzenia przesądziły jednak o wyborze uproszczonego rozwiązania. Sama jednostka arytmetyczno-logiczna, czyli ALU, jest w pełni 16-bitowa. Niestety nie zdecydowano się na wyposażenie rdzenia w osobną jednostkę do operacji na adresach.
Rejestry indeksowe X i Y są 16-bitowe i niezależnie od innych funkcji mogą zostać ograniczone do 8-bitów za pomocą znacznika X, czyli bitu wyboru trybu indeksowania (ang. index select bit). Znacznik X pełni w przypadku rejestrów indeksowych podobną funkcję jak znacznik M w przypadku operacji związanych z akumulatorem.
W celu rozszerzenia przestrzeni adresowej do 16 MiB, czyli do 24-bitowego adresu, zastosowano technikę bankowania. Adres banku to najbardziej znaczące 8 bitów, a wartość adresu efektywnego wynikającego z instrukcji określa mniej znaczące 16 bitów. W przypadku instrukcji operujących na danych numer banku określa DBR (ang. data bank register - rejestr banku danych), w przypadku adresu instrukcji wykorzystywany jest PBR (ang. program bank register - rejestr banku programu). Licznik programu PC określa mniej znaczące 16 bitów w ramach banku określonego przez PBR. Kod programu może przekroczyć 64 KiB, jednak pojedyncza sekwencja kodu musi mieścić się w jednym banku, przepełnienie rejestru PC nie inkrementuje automatycznie wartości w rejestrze PBR.
Specjalne znaczenie ma obszar 0x000000 - 0x00FFFF, czyli tzw. bank 0. Stos oraz obszar tzw. adresowania bezpośredniego są ograniczone właśnie do tego banku. Tryb adresowania bezpośredniego stanowi uogólnienie i rozszerzenie koncepcji „strony zerowej” znanej z MOS 6502. W tym trybie wartość 16-bitowego rejestru D (ang. direct - bezpośredni) dodawana jest do 8-bitowego przesunięcia, wynik jest „obcinany” do 16-bitów i stanowi adres efektywny.
Pomimo oczywistych wad wykorzystanie banków daje taką zaletę, że adres wewnątrz banku może być krótszy, więc jako operand zajmuje mniej miejsca w pamięci. Reasumując, następująca instrukcja:
LDA $2000
| w zależności od wartości bitu M załaduje do akumulatora bajt albo 16-bitowe słowo w formacie little-endian, spod adresu DBR | 0x2000 do 16-bitowego akumulatora. W trybie 8-bitowym bardziej znaczący bajt akumulatora jest zerowany. Analogicznie funkcjonują rejestry indeksowe w zależności od wartości bitu X. |
W celu ułatwienia stosowania mikroprocesora w systemach wieloprocesorowych wyprowadzono na zewnątrz sygnały ułatwiające koordynację dostępu do zasobów, arbitrażu magistrali czy stosowania pamięci podręcznej (ang. cache). Dostępne są następujące sygnały modułu kontroli systemowej (ang. system control) służące do koordynacji pracy w większych systemach:
MLB(ang. memory lock - blokada pamięci) - może być wykorzystany do zapewnienia spójności (dostępu atomowego) dla sekwencji operacji odczyt-modyfikacja-zapis w systemach wieloprocesorowych.VDA(ang. valid data address - prawidłowy adres danych) - na szynie adresowej jest prawidłowy adres danych. Sygnał może być wykorzystany do implementacji cache dla danych.VPA(ang. valid program address - prawidłowy adres programu) - na szynie adresowej znajduje się prawidłowy adres instrukcji programu. Sygnał może być wykorzystany do implementacji cache dla kodu.VPB(ang. vector pull - pobieranie wektora) - podczas procedury obsługi przerwania sygnał jest aktywny w cyklach, w których procesor pobiera bajty adresu procedury obsługi i ładuje je do rejestru PC. Umożliwia to zmianę wektora „w locie” i tym samym uzależnienie go od źródła zgłaszającego przerwania, a także wprowadzenie priorytetów obsługi itd.E(ang. emulation - emulacja) - odzwierciedla stan znacznika E, może być wykorzystany do rozszerzenia listy rozkazów w połączeniu z kodem operacji.MX(ang. memory/index - pamięć/indeks) - podczas opadającego zbocza sygnału zegarowego ma stan znacznika M, a podczas narastającego zbocza stan znacznika X. Sygnał może zostać wykorzystany przez logikę zarządzającą dostępem do pamięci.
Projektanci, a w zasadzie główny projektant Bill Mensch, dołożyli starań, by tak prosta konstrukcja, jaką był MOS 6502, po rozszerzeniu stała się bardziej wydajna, uniwersalna, lecz przy minimalnym wzroście poziomu komplikacji. Niestety w głównym nurcie rozwoju komputerów osobistych WDC 65C816 nie trafił idealnie w swój czas i jego potencjał nie został w pełni wykorzystany. Zastosowano go w komputerze Apple IIgs, który jednak ze względu na politykę firmy był skazany na nieuchronne wycofanie z oferty. Konkurencyjny projekt Apple Macintosh był silnie promowany, do tego stopnia, że częstotliwość zegara w Apple IIgs została celowo obniżona z 4 Mhz do 2.8 MHz, by nie mógł z nim konkurować wydajnością. Wkrótce ukazały się wersje WDC 65C816 z taktowaniem od 5 do nawet 14 MHz przy niewielkiej różnicy w cenie. Apple jednak nie zdecydowało się ich wykorzystać, pozostając przy zegarze 2.8 MHz do końca produkcji modelu IIgs. Będąc zdecydowanie prostszym i mniej zaawansowanym mikroprocesorem, WDC 65C816 może przy takim samym zegarze, wykonać więcej dodawań 64-bitowych niż Motorola 68000. Nawet tak prosty benchmark pokazuje, że zagrożenie dla Macintosha, przy prostszych zadaniach, było wówczas realne. Podstawowe dane omawianego mikroprocesora podane są w poniższej tabeli.
| rok wprowadzenia do produkcji | 1983 |
| ilość tranzystorów | 22000 |
| częstotliwość taktowania | 4 MHz (cykl zegarowy: 0.25 μs) |
| najkrótszy cykl instrukcji | 0.5 μs (2 cykle zegarowe) |
| indeks prędkości | 2 MIPS |
| dodawanie 64-bitowe | 39215 / s |
| efektywność architektury | 1783 |
| typ architektury | 8/16-bit, CISC |
| kolejność bajtów | little-endian |
| licznik programu | 8-bit bank : 16-bit offset |
| stos | 16-bit |
| rejestry ogólnego przeznaczenia | 2 x 8-bit |
| rejestry indeksowe | 2 x 16-bit |
| rejestry banków pamięci | 2 x 8-bit, 16-bit strony bezp. DP |
| ALU | 16-bit ogólnego przeznaczenia |
| adresowanie pamięci | 16 MiB (24-bit adres), adresowanie z bankowaniem |
| adresowanie portów | w obszarze pamięci |
| przerwania | niemaskowalne, maskowalne, programowe |
| dzielenie i mnożenie liczb całkowitych | nie |
| tryby pracy | emulacja 6502 / natywny 16-bit |
| praca z koprocesorem | tak |
| systemy wieloprocesorowe | tak |
Tryby adresowania:
- domyślne
- natychmiastowe
- bezpośrednie 8-bitowe
- bezpośrednie
- bezpośrednie indeksowane
- pośrednie
- pośrednie indeksowane
- indeksowane pośrednie
- blokowe
- względne
Znaczniki:
N- znakV- przepełnienieM- tryb dostępu do pamięci: 8/16-bitB- przerwanie programoweX- tryb rejestrów indeksowych: 8/16-bitD- tryb dziesiętnyI- maska przerwańZ- zeroC- przeniesienie
Dostęp do dodatkowych funkcji i znaczników mikroprocesora realizuje 78 nowych operacji, z których kilka zostanie przedstawione poniżej:
MVP (ang. move previous - przenieś wstecz) - przenieś blok pamięci z dekrementacją indeksów. 16-bitowy akumulator C musi zawierać długość przenoszonego bloku minus jeden, a rejestry X i Y końcowe adresy obszarów źródłowego i docelowego. Instrukcja ma dwa 8-bitowe operandy określające bank źródłowy i docelowy.
MVN (ang. move next - przenieś wprzód) - przenieś blok pamięci z inkrementacją indeksów. Przeznaczenie rejestrów jest analogiczne jak w instrukcji MVP z tą różnicą, że rejestry X, Y zawierają adresy początków obszarów.
COP (ang. coprocessor enable - włącz koprocesor) - wywołuje programowe przerwanie, adres procedury obsługi określa specjalny wektor dla instrukcji COP. Przerwanie może zostać przechwycone przez układy zewnętrzne i wykorzystane do współpracy z zewnętrznym koprocesorem.
PHB, PHD, PHK, PLB, PLD, PLK - odłóż na stosie lub pobierz ze stosu rejestry odpowiednio: segmentu danych (DBR), rejestru adresowania bezpośredniego (D) lub segmentu programu (PBR).
JSL, RTL - skocz do podprogramu i powróć z podprogramu wykorzystując „długi” adres, czyli odkładając na stos i odtwarzając z niego 16-bitowe przesunięcie wraz z 8-bitowym segmentem.
Zostały dodane również instrukcje transferu obsługujące nowe rejestry oraz nowe znaczniki. Kod standardowego benchmarku dla WDC 65C816 przedstawiony jest poniżej.
; Western Digital Center WDC65816
; dodawanie dwóch liczb 64-bitowych
; ARG0, ARG1 - etykiety buforów zawierających argumenty
; wynik zapisywany jest w ARG1, dane zorganizowane są w 16-bitowe słowa
; kolejność bajtów w słowie zgodna z wymaganą przez architekturę procesora,
; słowa w buforze w kolejności od najmniej znaczącego
; włączony jest tryb natywny (znacznik E=0)
; rejestry indeksowe ustawione są w tryb 8-bitowy (znacznik X=1)
; dostęp do pamięci i akumulator ustawione są w tryb 16-bitowy (znacznik M=0)
SEP #$20 ; (3) ustaw 16-bitowy dostęp do pamięci i rej. A
LDX #0 ; (2) zeruj indeks słowa
CLC ; (2) zeruj znacznik przeniesienia
NST:
LDA ARG0, X ; (5) ładuj do A kolejne słowo z ARG0
ADC ARG1, X ; (5) dodaj do A kolejne słowo z ARG1
STA ARG1, X ; (5) zapisz wynik do bieżącego słowa z ARG1
INX ; (2) zwiększ indeks słowa o 1
INX ; (2) zwiększ indeks słowa o 1
CPX #4 ; (2) porównaj indeks słowa z długością argumentu
BNE NST ; (3) kontynuuj jeśli nie wszystkie słowa dodano
Sumując czasy wykonania, dostajemy: 7 + 4 x 24 - 1(ostatni skok warunkowy nie zachodzi więc zajmuje mniej cykli) = 102 cykle zegara. Czas wykonania wynosi więc 25.5 μs, co daje 39215 dodawań na sekundę.
W chwili pisania tego artykułu mikroprocesor ten jest wciąż produkowany przez firmę Western Design Center i dostępny bezpośrednio w sklepie firmowym oraz w wielu znanych sieciach dystrybucyjnych.
Podsumowanie
Główny nurt rozwoju procesorów 16-bitowych to konstrukcje Intela wykorzystywane w komputerach osobistych klasy PC/XT oraz AT. Rachunek ekonomiczny, kompatybilność z poprzednimi modelami oraz bieżące wykorzystanie trendów rynkowych i technologicznych wymuszały niejednokrotnie zagmatwanie architektury i zbyt dużą ostrożność we wprowadzaniu nowych rozwiązań. Firmy mające mniejszy udział w rynku tradycyjnie musiały podejmować ryzyko i stawiać na innowacje (jak Motorola) lub na większą efektywność i uniwersalność za mniejszą cenę (jak Zilog). W tej klasyfikacji mikroprocesor WDC jest nostalgiczną próbą zatrzymania czasu przez wykazanie, że stare ścieżki wciąż prowadzą do celu, choć może nie tak wygodnie i szybko jak nowoczesne autostrady.
Źródła i bibliografia
W powstaniu niniejszego artykułu wykorzystane zostały następujące publikacje i źródła:
- 16-bit Microprocessor Systems …, Flik & Liebig, Springer-Verlag 1985.
- The 8086 Family User’s Manual, Intel Corporation 1978, 1979.
- Z8000 CPU User’s Reference Manual, 1980-1982 Zilog Inc.
- The Z8000 Microprocessor. A Design Handbook. Fawcett. Zilog Inc. 1982.
- Design Philosophy Behind Motorola 68000, Starnes, Byte Magazine 1983.
- Motorola M68000 Family Programmer’s Reference Manual, Motorola Inc. 1992.
- Intel Microprocessors, Architecture, Programming, Interfacing… (wyd. 8) , Brey, Pearson Education,1987-2009.
- Intel iAPX 286 Programmer’s Reference Manual, Intel Inc. 1985.
- Intel 80286 High Performance Microprocessor Datasheet, Intel Corp. 1988.
- Programming the 65816, Including the 6502…, The Western Design Center Inc. 2007.
- 65xx W65C816S 8/16-bit Microprocessor, The Western Design Center Inc. 1981-2018.
- Defuse
- Wikipedia
- Wikichip